 Open het menu
Open het menu sluit het menu
sluit het menu Bel: 074-2915208
Bel: 074-2915208
Dankzij Data Science zijn we in staat om beter, sneller en efficiënter data gestuurde beslissingen te nemen, op basis van bestaande data. Met behulp van Machine Learning kunnen we patronen herkennen binnen data uit het verleden om uitspraken te kunnen doen over nieuwe data, of zelfs de toekomst te kunnen voorspellen. Voor velen lijkt het nog een “ver-van-mijn-bed-show” om deze technieken toe te passen binnen hun organisatie, maar het wordt steeds makkelijker en laagdrempeliger om dit in de praktijk te implementeren.
Kant-en-klare modellen en algoritmen zijn gratis beschikbaar en gebruiksvriendelijk beschikbaar voor iedereen. Het blijft alleen een kwestie van het opstellen van de juiste dataset en het maken van de juiste keuzes voor de modellen op basis van de data en het doel. Hiervoor koppelen we verschillende databronnen aan elkaar, selecteren daaruit de juiste data en bewerken en filteren dit. Zo maken we data begrijpelijk en beschrijvend voor een algoritme om de patronen in de data te kunnen leren.
Data Science oplossingen zijn te verdelen in drie categorieën: Predictive, Automation en Optimisation. Aan de hand van deze categorieën is ook zeer eenvoudig te verduidelijken dat Data Science geen complexe materie hoeft te zijn.
Met Predictive Data Science vervangen we intuïtie en ervaring door data en reduceren we de error marge van prognoses. Predictive oplossingen maken gebruik van geavanceerde analyses, en door te zoeken naar patronen in actuele data en data uit het verleden zijn we in staat de toekomst te voorspellen
Er zijn meerdere punten waar een organisatie predictive oplossingen kan integreren voor een verbeterde dagelijkse operatie. Zo kan een manager bijvoorbeeld middelen toewijzen aan nieuwe projecten op basis van nauwkeurige voorspellingen over wanneer lopende projecten afgerond zullen worden. HR-afdelingen kunnen vragen om meer personeel aan te nemen als ze binnenkort een zwaardere werkdruk verwachten. En in sales zijn nauwkeurige prognoses van cruciaal belang voor budgettoewijzing, vraag- en aanbod beheer, prestatie stimulering en het opstellen van de zakelijke roadmap.
Enkele eenvoudig te herkennen voorbeelden van Predictive Data Science zijn:
– Accurate sales prognoses leveren;
– Factuur betaling voorspellen;
– Jaarlijkse omzet voor een nieuw filiaal voorspellen;
Door te automatiseren met behulp van data science maken we bestaande processen beter, sneller en goedkoper. Het automatiseren van simpele processen is iets wat we al veel zien. Maar met behulp van data science is het mogelijk om zelfs de meest complexe processen te automatiseren. Een mooi voorbeeld hiervan is een chatbot. Aangezien de technologie achter chatbots zodanig is geëvolueerd, kunnen chatbots intussen gebruik maken van Natural Language Processing(NLP) en zijn ze uitgegroeid van eenvoudige hulpmiddelen tot onmisbare tools die op een heel menselijk en persoonlijk aanvoelende manier met consumenten in contact kunnen treden. Deze slimme chatbots kunnen in de praktijk worden toegepast in verschillende situaties zoals klantenservice en verkoop.
Ook het verwerken van klantenrecensies kan tegenwoordig op een slimme manier geautomatiseerd worden. Met NLP kan gekeken worden naar wat klanten zeggen, specifieke terugkerende onderwerpen identificeren, kijken naar het sentiment van de klant en het consumenten gesprek als geheel begrijpen. Met behulp van machine learning worden de gegevens uit deze recensies geanalyseerd en gebruikt om profielen van klanten op te bouwen en patronen te herkennen die zich voordoen om inzicht te geven in hoe klanten denken en handelen.
Enkele eenvoudig te herkennen voorbeelden van Automation met Data Science zijn:
– Chatbots inzetten als customer service;
– Alternatieven aanbieden in webshops;
– Klantrecensies classificeren en labelen;
Veel processen kunnen op basis van data geoptimaliseerd worden. Door de juiste databronnen aan elkaar te koppelen en daaruit de juiste data te selecteren maken we processen efficiënter, sneller en besparen we resources. Voorbeelden van wat we met Optimisation kunnen:
– De meest efficiënte pickroute bepalen voor een orderpicker;
– De bezorgroutes en het laden van vrachtwagens optimaliseren;
– Het voorraadbeheer voor retailers optimaliseren;
Door middel van een bewezen standaard traject voor data science projecten voor bedrijven wordt een data science project in goede banen geleid. Dit data science-traject is een systematische benadering voor het oplossen van een data science probleem. Het biedt een gestructureerd kader om problemen als een vraag te formuleren, te oplossing route te beslissen en vervolgens de oplossing aan belanghebbenden te presenteren. Het traject is bewezen succesvol, verloopt altijd in continue afstemming met relevante stakeholders en kent de volgende zes fases:
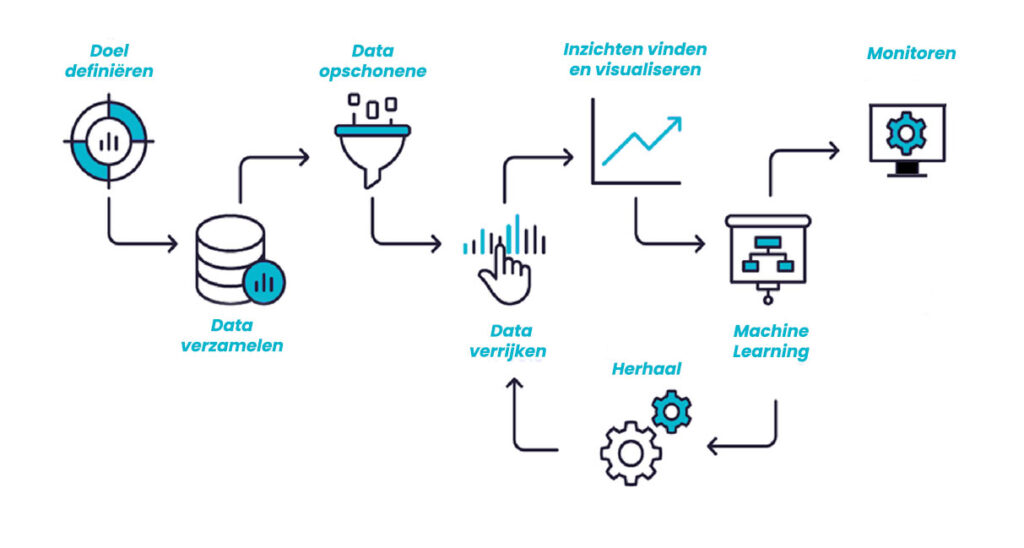 1. Zakelijk begrip
1. Zakelijk begripDe eerste stap in het proces is om de bedrijfsdoelen te verduidelijken en focus te brengen op het data science-project. Binnen een duidelijke definitie van het doel dient naast het identificeren van de te berekenen waardes ook gedefinieerd worden hoe deze waarden invloed gaan uitoefenen op de bedrijfsvoering in de praktijk. Om het bedrijf beter te begrijpen, ontmoeten data scientists belanghebbenden materiedeskundigen en anderen die inzicht kunnen bieden in het probleem dat zich voordoet. Ze kunnen ook vooronderzoek doen om te zien hoe anderen soortgelijke problemen hebben geprobeerd op te lossen. Uiteindelijk wordt een duidelijk probleem gedefinieerd met daarbij een routekaart om het op te lossen.
De volgende fase is het begrijpen van de data. In deze fase wordt bepaald welke data er beschikbaar is, wat de data inhoudt en wat de kwaliteit ervan is. Er wordt besloten welke tools gebruikt worden voor gegevensverzameling en hoe de eerste gegevens verzamelt worden. Vervolgens worden de eigenschappen van de initiële gegevens beschreven, zoals het formaat, de hoeveelheid en de beschikbare velden van de datasets. Na het verzamelen en beschrijven van de gegevens wordt een eerste data exploratie gedaan. De eerste hypotheses kunnen geformuleerd worden en de kwaliteit van de data wordt gevalideerd om foutieve of missende gegevens te identificeren.
Data afkomstig uit verschillende bronnen zijn als ruwe data meestal onbruikbaar, omdat er vaak velden ontbreken, of tegenstrijdige waarden en uitschieters zijn. Deze problemen worden tijdens deze fase opgelost en de kwaliteit van de data wordt verbetert, zodat deze effectief gebruikt kunnen worden. Naast de datakwaliteit verbeteren worden in deze fase ook nieuwe velden gegenereerd door middel van transformaties op bestaande velden. Het doel is om goede beschrijvende of predictieve velden te genereren die een model goed kan gebruiken om patronen in de data te herkennen en te leren. Deze fase wordt vaak meerdere keren doorlopen tijdens het project om het uiteindelijke model iteratief te optimaliseren.
Tijdens deze fase wordt op basis van de beschikbare data gespecificeerd welke modelleringstechnieken geschikt zijn voor het oplossen van het probleem. Daarbij horen ook de assumpties die gemaakt worden per model. Voor de geselecteerde modelleringstechnieken worden tests ontworpen om de kwaliteit van het model te bepalen. Ook wordt besloten welke data gebruikt gaat worden voor het trainen van het model en welke voor het evalueren van het getrainde model. Vervolgens worden de modellen ontwikkeld met daarbij een beschrijving van de modellen en de gebruikte parameter instellingen. Tot slot wordt een beoordeling gemaakt van de modellen, met daarbij een ranking van de verschillende modellen. Na deze beoordeling kunnen de gebruikte parameters herzien worden om een nieuwe modellering ronde te starten.
Tijdens de evaluatiefase worden de modellen geëvalueerd op basis van de bedrijfsdoelstellingen. Ook het proces zelf wordt geëvalueerd en worden eventuele correcties aangebracht. Een samenvatting van de bevindingen en het model wordt gepresenteerd. Ten slotte wordt bepaald of het model gereed is voor deployment, of dat er een nieuwe iteratie nodig is om het model verder te optimaliseren.
Tijdens deze fase wordt het model geïmplementeerd. Het model wordt in productie genomen om live data te gebruiken en te verwerken naar de gewenste output. Daarnaast wordt de output van het model gemonitord om de kwaliteit te bewaken. Het project wordt afgesloten met een oplevering van een rapport van het proces en het model, met daarbij een presentatie aan de stakeholders.
Met een combinatie van de juiste knowhow, kant-en-klare modellen en algoritmen, talloze beschikbare voorbeelden en een bewezen gestandaardiseerd traject, is het tegenwoordig mogelijk om een data science oplossingen binnen afzienbare tijd succesvol te realiseren. Dit maakt het mogelijk om laagdrempelig meerwaarde te realiseren, zonder dat daarbij de kosten uit de pan hoeven te rijzen.
Wil je meer weten over Data Science? Op 7 september geven wij een webinar. In deze webinar laten we je zien dat data science geen ver-van-je-bed-show meer is. Van begin tot eind nemen we je mee in de reis hoe je een data science traject opzet met praktische voorbeelden die laten zien dat je met een kleine investering veel resultaat boekt. Aanmelden kan via deze link.
